2021. 5. 6. 23:44ㆍ머신러닝
학습한 모델의 성능을 평가하는 것에 중요성은 모두가 공감할 것이라고 생각합니다. 특히 새로운 데이터에도 일관된 성능을 가지는 모델을 구현하는 것은 해당 모델의 성능과 아주 밀접한 관련이 있습니다.
이러한 일관된 성능과 관련된 개념이 Bias, Variance 그리고 Model Complexity 입니다.
Bias와 Variance와 관련하여 아주 유명한 그림 하나를 살펴보겠습니다.

Bias는 Underfitting과 관련된 것으로, 적합한 성능을 내기 위한 정보들을 모두 활용하지 못하여 정확성이 떨어진 것을 말합니다. Variance는 Overfitting과 관련된 것으로 너무 많은 정보를 고려한 나머지 Training set에만 잘 맞는 모형을 적합한 것입니다.
일반적으로 Model Complexity가 너무 높아지게 되면(너무 많은 정보를 고려하게 되면) Low Bias, High Variance가 될 위험이 있으며, 이 관계도 유명한 그림을 첨부하겠습니다.
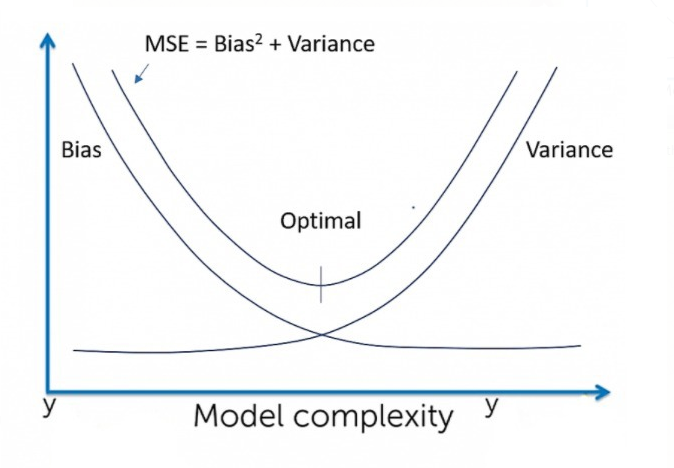
일반적으로 Triang data $T$에 대해서 학습한 모델 $f(X)$에 대해서 새로운 Test Sample 예측값 $\widehat{f}(X)$와 실제값 Y의 오차($Err_T$)를 최소화하는 것이 머신러닝 모델을 구축하는 목적이 되곤합니다. 즉, 아래와 같은 오차를 최소화 하는 모델을 찾는 것이 중요한 goal중에 하나입니다.

'머신러닝' 카테고리의 다른 글
| 모델 평가 및 선정 > In-Sample Prediction(2/2) (0) | 2021.05.30 |
|---|---|
| 모델 평가 및 선정 > In-Sample Prediction (0) | 2021.05.13 |
| 커널 밀도 추정 기반 Classification (0) | 2021.04.19 |
| 커널 밀도 추정(Kernel Density Estimation, KDE) (0) | 2021.04.12 |
| KRR(Kernel Ridge Regression) (0) | 2021.03.23 |