2020. 12. 27. 00:07ㆍ계량경제학
지난 포스팅(https://direction-f.tistory.com/67)에서 AR(1)모델을 우리는 MA(∞)으로 나타낼 수 있으며, MA(1)모형을 AR(∞)로 표현할 수 있음을 확인했습니다. 이러한 가역성 특징을 활용하여 어떤 시계열 모형울 수립할때, AR모형과 MA모형을 함께 사용하는 것이 효율적인 경우가 많습니다.
ARMA모형은 AR모형과 MA모형을 섞어서 일반적으로 아래와 같이 표현됩니다.
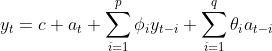
ARIMA 모형은 ARMA모형과 모양은 거의 유사하지만 우리가 가지고 있는 시계열 데이터에 대해서 차분(differencing)을 하느냐 입니다. ARMA모형은 정상성을 가진 시계열 데이터를 활용하여 모델링을 해야 하기 때문에, 시계열 데이터가 정상성을 가지지 않는다면 차분을 통해 정상 시계열 데이터로 만들어야 합니다. 따라서 이러한 차분을 수행하게 된다면 ARMA모형은 ARIMA모형이 됩니다. 이때 I는 integrated를 의미하며, 차분의 수행한 수를 뜻하게 됩니다.
그렇다면 이제 우리가 ARMA모형이나 ARIMA모형을 사용한다고 한다면, AR모형과 MA모형의 차수(lag)를 선택하기 위해서는 어떤 방법을 사용해야 할까요? 이 때 많이 활용 되는 것이 Box-Jenkins모델링 프로세스 입니다.
Box-Jenkins모델링 프로세스는 서적이나 자료마다 조금씩 다르게 표현되고 있지만, 크게 아래와 같은 순서를 따르게 됩니다.
1) Data Processing -> 2)Indentification -> 3)Estimation- > 4)Diagnosis -> 5) Analysis/Forecasting
이번 포스팅에서는 4) Diagnosis까지 다루어보도록 하겠습니다.
[Data Processing]
Data Processing은 단어에서부터 쉽게 짐작할 수 있듯이, 시계열 모델링을 하기 위해서 데이터 처리를 수행하는 것이며, 여기서는 차분을 얼마만큼 해야하는지까지 결정하도록 합니다. 이전 포스팅에서 정리했던 것과 동일하게 Data를 Load하고 기본적인 처리를 수행합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats
import os
sns.set()
org_path = "--/Time series"
os.chdir(org_path)
## Data loading
raw_csv_data= pd.read_csv("snp_index.csv")
df = raw_csv_data[["Date","Close"]].copy()
## from text to date
df.Date = pd.to_datetime(df.Date, dayfirst = False)
## setting index
df.set_index("Date", inplace = True)
df=df.asfreq(freq="B")
## fillna
df=df.fillna(method='ffill')
## Splitting the data
size = int(len(df)*0.8)
df_train = df.iloc[:size]
df_test = df.iloc[size:]필요한 함수 및 Module을 import하고 원본 데이터의 ACF, PACF 그래프를 표현해보고 ADF 테스트를 통해서 정상성을 검증해보겠습니다.
## time series package
import statsmodels.graphics.tsaplots as sgt
import statsmodels.tsa.stattools as sts
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.arima_model import ARMA
from scipy.stats.distributions import chi2
import warnings
warnings.filterwarnings("ignore")
def LLR_test(mod_1, mod_2, DF=1):
L1 = mod_1.llf
L2 = mod_2.llf
LR = (2*(L2-L1))
p = chi2.sf(LR, DF).round(3)
return p
## additive - y(t) = Level + Trend + Seasonality + Noise
decomposition =seasonal_decompose(df["Close"], model = "additive", period =1)
fig = decomposition.plot()
fig.set_size_inches(10,10)
plt.show()
## ACF, PACF
fig = plt.figure()
ax1 = fig.add_subplot(2, 1, 1)
ax2 = fig.add_subplot(2, 1, 2)
sgt.plot_acf(df['Close'], lags = 20, zero = False, ax=ax1)
ax1.set_title("ACF S&P")
sgt.plot_pacf(df['Close'], lags = 20, zero = False, method = ('ols'), ax=ax2)
ax2.set_title("PACF S&P")
plt.show()
## ADF
sts.adfuller(df["Close"])
'''
(1.0596246474072912,
0.9948568682915807,
6,
6774,
{'1%': -3.43131571888621,
'5%': -2.8619667679228646,
'10%': -2.5669971648470256},
55484.34577265247)
'''
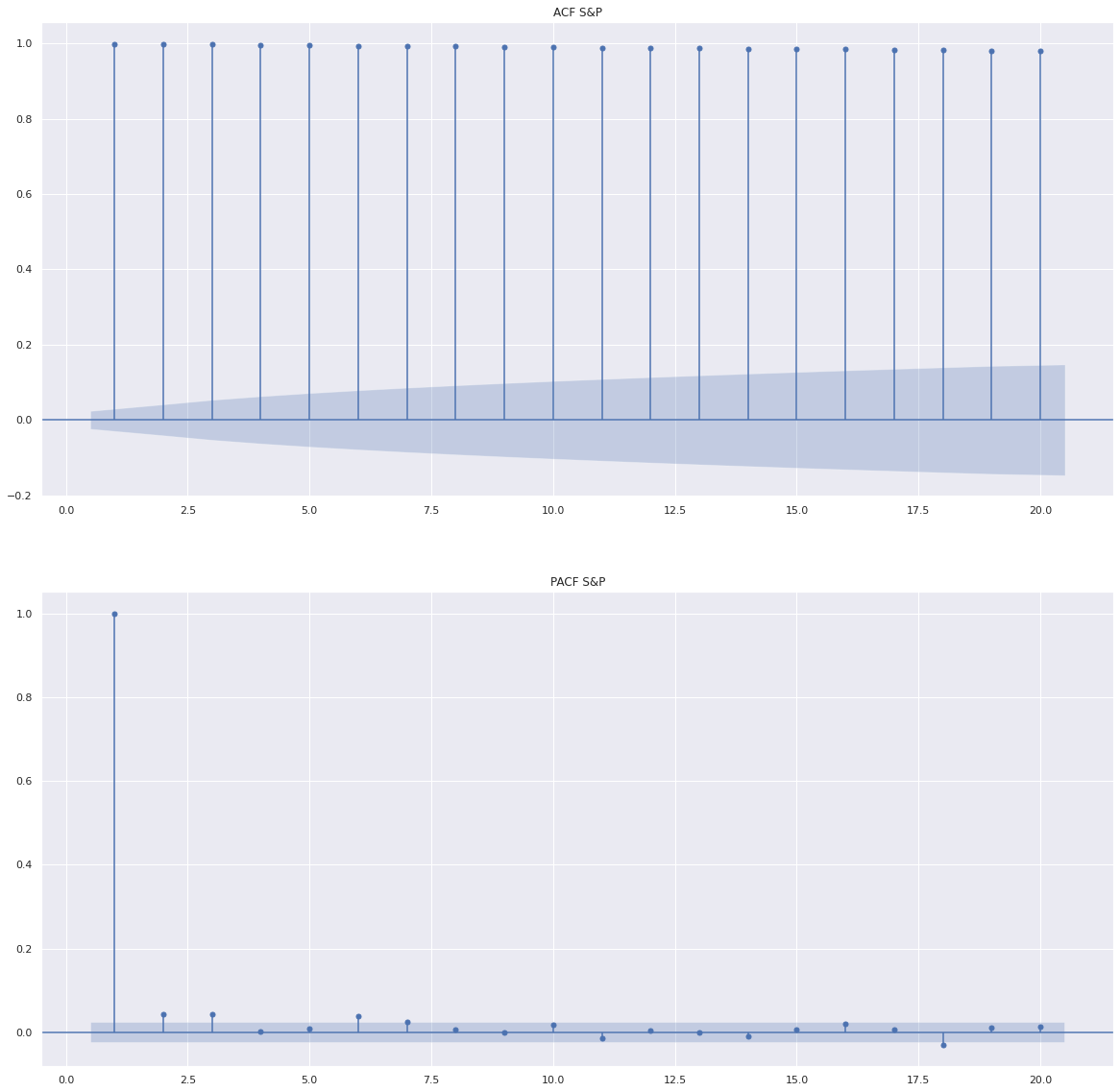
ACF 그래프를 보게 되면, 그 값이 지수적 또는 사인함수 형태로 감소하지 않고 ADF 검정 결과 p-value가 0.9이상으로 Null Hypothesis를 기각할 수 없어 Non-stationary란 것을 확인할 수 있습니다. 따라서 추가적으로 시계열 모델링을 하기 전에 차분과 같은 방법을 통해서 우리가 가지고 있는 데이터를 Stationary하게 변경할 필요가 있음을 알 수 있습니다. 즉, 우리가 가지고 있는 시계열 데이터는 ARIMA모형 적용이 필요하다는 것을 알 수 있습니다. 다만 먼저 차분 수행하고 차분한 데이터를 활용한다면 ARMA모형을 활용해도 결과는 동일합니다.
[Identification]
차분을 수행하고 우리가 어떤 ARMA 모형을 Fitting 해야할지 알아보도록 하겠습니다.
df["diff_Close"]=df["Close"].diff()
## ACF, PACF
fig = plt.figure()
ax1 = fig.add_subplot(2, 1, 1)
ax2 = fig.add_subplot(2, 1, 2)
sgt.plot_acf(df["diff_Close"].iloc[1:], lags = 20, zero = False, ax=ax1)
ax1.set_title("ACF S&P Diff")
sgt.plot_pacf(df["diff_Close"].iloc[1:], lags = 20, zero = False, method = ('ols'), ax=ax2)
ax2.set_title("PACF S&P Diff")
plt.show()
## ADF
sts.adfuller(df["diff_Close"].iloc[1:])
'''
(-36.399797684021294,
0.0,
5,
6774,
{'1%': -3.43131571888621,
'5%': -2.8619667679228646,
'10%': -2.5669971648470256},
55476.15067475778)
'''

우리가 가지고 있는 데이터를 차분하게 되면, ADF 검정결과 Stationary데이터가 됨을 확인할 수 있습니다. 다만 ACF, PACF를 확인하게 되면 17차수에서 다시 한번 시차가 유의하게 나옴으로써, 정확한 차수 p,q를 설정하는 것이 쉽진 않아보입니다. 계절성의 영향일 수도 있습니다. 다만 이번 포스팅에서는 ARMA 모형을 활용할 예정이기 때문에 17차수에 튀는 값은 무시하고 AR은 6차까지 그리고 MA는 5차까지 설정하고 모형을 수립하여 진단을 해보겠습니다.
ACF와 PACF를 대략적으로 해석하는 방안은 https://direction-f.tistory.com/65를 확인하시면 됩니다.
'계량경제학' 카테고리의 다른 글
| 시계열(Time series) > ARIMAX, SARIMA, SARIMAX (2) | 2021.01.01 |
|---|---|
| 시계열(Time series) > Diagnosing Models(ARMA, ARIMA)(2/2) (0) | 2020.12.27 |
| 시계열(Time series) > Moving average model(이동평균모형) (2) | 2020.12.23 |
| 시계열(Time series) > Autoregressive model(자기회귀모형) (1) | 2020.12.21 |
| 시계열(Time series) > ACF, PACF (0) | 2020.12.19 |