2020. 12. 23. 00:02ㆍ계량경제학
Moving average(MA) 모형은 앞선 포스팅에서 정리한 AR 모형과 함께 시계열 데이터를 활용한 모형을 수립하는데 활발히 적용되고 있는 모형입니다. AR 모형은 과거의 값을 활용하여 미래를 예측하는데 반해, MA 모형은 과거의 예측 오차를 활용하여 미래를 예측하는데 활용합니다.
가장 기본적은 MA(1) 모형은 다음과 같습니다.
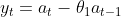
AR 모형과 마찬가지로 일반적인 MA(q) 모형은 아래와 같습니다.
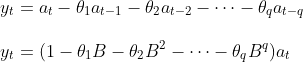
MA 모형도 AR 모형과 마찬가지로 계수 \theta가 -1과 1사이의 값을 가지게 됩니다.
정상성을 가지는 어떤 AR(1)모델을 우리는 MA(∞)으로 나타낼 수 있으며, MA(1)모형을 AR(∞)로 표현할 수 있습니다. 이러한 성질을 가역성(Invertibility)라고 표현합니다. 즉 AR모형을 과거의 예측 오차(Random shock)으로 표현하며, MA모형을 과거 값(Past observation)으로 나타낼 수 있다는 것을 뜻합니다.
먼저, AR(1) = MA(∞)에 대해서 정리해보도록 하겠습니다. AR(1) 모형은 다음과 같습니다.
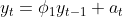
AR(1)모형은 다음과 같이 표현할 수 있습니다.
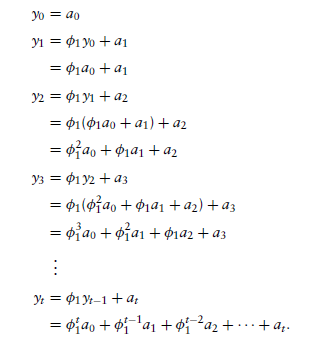
최종적으로,
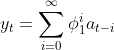
풀어서 표현하면 아래와 같습니다.
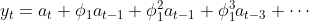
이는 MA 모형과 모습이 동일함을 확인할 수 있습니다.
MA(1) = AR(∞)도 위와 비슷한 흐름으로 정리하게 되면 최종적으로 아래와 같이 MA(1) 모형을 표현할 수 있습니다.
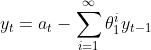
위와 같이 AR 모형과 MA 모형은 서로 관계를 가지고 있으며, 시계열 모형을 수립하는데 AR 모형과 MA 모형을 함께 고려할 수 있습니다.(ARMA) 또한 효과적으로 모형을 Identification하기 위해서는, AR 모형과 MA 모형을 동시에 고려하여 구축하고자 하는 시계열 모형을 선택하는 것이 바람직할 것입니다.
이제 간단히 Python을 활용하여 MA 모형을 구현해보겠습니다.
### MA model
from statsmodels.tsa.arima_model import ARMA
##MA(1)
model_ma_1 = ARMA(df["Close"], order = (0,1))
result_ma_1 = model_ma_1.fit()
result_ma_1.summary()
'''
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
const 1401.8593 7.599 184.487 0.000 1386.966 1416.752
ma.L1.Close 0.9828 0.002 629.625 0.000 0.980 0.986
'''
##MA(2)
model_ma_2 = ARMA(df["Close"], order=(0,2))
results_ma_2 = model_ma_2.fit()
results_ma_2.summary()
'''
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
const 1401.7803 7.871 178.087 0.000 1386.353 1417.208
ma.L1.Close 1.7819 0.005 394.608 0.000 1.773 1.791
ma.L2.Close 0.9236 0.004 263.282 0.000 0.917 0.930
'''
##MA(3)
model_ma_3 = ARMA(df["Close"], order=(0,3))
results_ma_3 = model_ma_3.fit()
results_ma_3.summary()
'''
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
const 1401.9427 8.339 168.123 0.000 1385.599 1418.286
ma.L1.Close 2.2514 0.011 201.460 0.000 2.229 2.273
ma.L2.Close 2.1177 0.011 187.115 0.000 2.096 2.140
ma.L3.Close 0.8159 0.006 147.389 0.000 0.805 0.827
'''
##MA(4)
model_ma_4 = ARMA(df["Close"], order=(0,4))
results_ma_4 = model_ma_4.fit()
results_ma_4.summary()
'''
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
const 1401.9952 8.840 158.594 0.000 1384.669 1419.322
ma.L1.Close 2.4337 0.010 233.354 0.000 2.413 2.454
ma.L2.Close 3.0048 0.016 183.050 0.000 2.973 3.037
ma.L3.Close 2.1267 0.012 170.693 0.000 2.102 2.151
ma.L4.Close 0.7359 0.007 104.766 0.000 0.722 0.750
'''## LLR test
from scipy.stats.distributions import chi2
def LLR_test(mod_1, mod_2, DF=1):
L1 = mod_1.fit().llf
L2 = mod_2.fit().llf
LR = (2*(L2-L1))
p = chi2.sf(LR, DF).round(3)
return p
LLR_test(model_ma_1, model_ma_2) ##0.0
LLR_test(model_ma_2, model_ma_3) ##0.0
LLR_test(model_ma_3, model_ma_4) ##0.0LLT test(참조: direction-f.tistory.com/66)를 보면 차수를 높일 수록 더 Fitting이 더 잘 되고 있습니다. 현재 비정상성을 띄는 S&P500 Index를 그대로 활용했습니다. 올바른 모형 Identification을 하기 위해서는, 이전에 정리했던 ADF Test ACF, PACF 등을 활용하여 모형을 결정해야합니다. 다음 포스팅에선 시계열 모형을 결정하기 위한 방안에 대해서 정리해보도록 하겠습니다.
'계량경제학' 카테고리의 다른 글
| 시계열(Time series) > Diagnosing Models(ARMA, ARIMA)(2/2) (0) | 2020.12.27 |
|---|---|
| 시계열(Time series) > Diagnosing Models(ARMA, ARIMA)(1/2) (0) | 2020.12.27 |
| 시계열(Time series) > Autoregressive model(자기회귀모형) (1) | 2020.12.21 |
| 시계열(Time series) > ACF, PACF (0) | 2020.12.19 |
| 시계열(Time series) > White Noise, Random walk (1) | 2020.12.06 |