2020. 9. 6. 20:48ㆍ데이터 분석 기본
카이제곱($\chi^2$)적합도 검정은 범주형 자료에 대한 가설을 검정하는 방안입니다. 쉽게 말하면, 교차테이블에 대한 가설검정입니다.
예를 들어 나이대별 E-commerce 사용자의 관측빈도를 아래와 같이 교차테이블로 표현할 수 있습니다.
| 나이대 | 20대 | 30대 | 40대 | 합계 |
| 관측도수 | 50 | 30 | 20 | 100 |
만약 모집단의 비율을 1/2, 1/4, 1/4으로 가정했을 때, 카이제곱($\chi^2$)적합도 검정을 통해 교차테이블로 얻은 정보로 모집단의 모집단의 비율을 기각 또는 채택할 수 있을지에 대한 검정을 하는 것입니다.
즉 이때 귀무가설은 아래와 같이 표현할 수 있습니다.
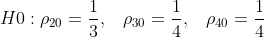
이와 같은 검정을 적합도 검정(goodeness-of-fit test)라고 부릅니다.
[적합도 검정(goodeness-of-fit test)]
범주별 관측도수 및 $H_0$에서의 기대도수가 아래와 같은 교차테이블로 주어졌다고 가정해보겠습니다.
| 범주 | 1 | 2 | $\cdots$ | $k$ | 합계 |
| 관측도수(O) | $n_1$ | $n_2$ | $\cdots$ | $n_k$ | $n$ |
| 기대도수(E) | $n\rho_1$ | $n\rho_2$ | $\cdots$ | $n\rho_k$ | $n$ |
$H_0$를 기각할지 말지를 결정하는 검정통계량으로는 아래와 같은 통계량이 활용됩니다.

이 때, 귀무가설 $H_0$과 기각역은 아래와 같습니다.

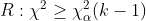
[동질성 검정(homogeneity test)]
위에 교차테이블은 하나의 그룹으로만 이루어진 것입니다. 하지만 아래와 같이 두 그룹 이상으로 이루어진 교차테이블을 구성할 수 있습니다.
| 범주 | 1 | 2 | $\cdots$ | $k$ | 합계 |
| A그룹 관측도수(O) | $n_{A1}$ | $n_{A2}$ | $\cdots$ | $n_{Ak}$ | $n_A$ |
| B그룹 관측도수(O) | $n_{B1}$ | $n_{B2}$ | $\cdots$ | $n_{Bk}$ | $n_B$ |
| 합계 | $n_1$ | $n_2$ | $\cdots$ | $n_2$ | $n$ |
이 때 귀무가설($H_0$)은 아래와 같이 나타낼 수 있습니다.
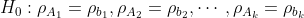
다만 여기서 카이제곱($\chi^2$)통계량을 쓰기 위해서는 기대도수(E)를 별도로 계산해주업니다. 기대도수(E)는 [해당 칸이 속한 행의 합계 *(칸이 속한 열의 합계/전체합계)]이며, 위의 표로 A그룹 범주1의 기대도수를 계산을 해보면 아래와 같습니다.
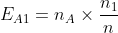
최종적으로, 검정통계량과 기각역은 아래와 같습니다.
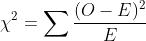
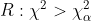
이 때 자유도는 [(행의 수-1)*(열의 수 -1)]이 됩니다.
Python을 통해 실습을 해보겠습니다.
from scipy.stats import chi2
from scipy.stats import chisquare
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import researchpy as rp
#### 적합도 검정 ####
## 데이터 생성
observed_, expected_ = [18,55,27], [25,50,25]
ct_1 = pd.DataFrame([observed_, expected_], columns=["1","2","3"], index=['A', 'B'])
ct_1
## 카이제곱검정 통계량 계산
observed = ct_1.loc["A"]
expected = ct_1.loc["B"]
chi_squared_test = (observed-expected).pow(2)/expected
chi_squared_statistic=chi_squared_test.sum()
print(chi_squared_statistic) ##2.62
## 카이제곱검정 수행(적합도 검정)
dof = 3-1
chi_ = chi2(dof)
chi_05 = chi_.ppf(0.95)
print(chi_05) ## 5.991464547107979
if chi_squared_statistic >= chi_05:
print("H0 기각")
else :
print("H0 채택")
## H0 채택 : 우리가 가정한 모집단과 다르다고 말할 수 없다
p_val=1-chi_.cdf(chi_squared_statistic)
print(p_val) ## 0.26982005638468687
## 모집단의 분포를 알고 있고, 이에 대해 검증할 때, 활용 package
chisquare(ct_.loc["A"].values,f_exp = ct_.loc["B"].values)
## 결과 Power_divergenceResult(statistic=2.62, pvalue=0.26982005638468687)
#### 동질성 검정 ####
x_a, x_b = [32,51,67,83], [268,199,233,267]
ct_2 = pd.DataFrame([x_a, x_b], columns=["A","B","C","D"], index=['1', '2'])
ct_2=ct_2.T
ct_2
## 카이제곱검정 통계량 계산(동질성 검정)
treatment_sum=ct_2["1"]+ct_2["2"]
sum_1 = ct_2["1"].sum()
sum_2 = ct_2["2"].sum()
sum_tot = sum_1+sum_2
expected_1 = treatment_sum*sum_1/sum_tot
expected_2 = treatment_sum*sum_2/sum_tot
expected=pd.concat([expected_1, expected_2], axis=1)
chi_squared_test = (ct_2[["1","2"]]-expected).pow(2)/expected
chi_squared_statistic=chi_squared_test.values.sum()
print(chi_squared_statistic) ##20.596749762391923
##카이제곱검정
dof = 3*1
chi_ = chi2(dof)
chi_05 = chi_.ppf(0.95)
print(chi_05) ## 7.814727903251179
if chi_squared_statistic >= chi_05:
print("H0 기각")
else :
print("H0 채택")
## H0 기각 집단 "A", "B", "C", "D"간의 차이가 있다.
p_val=1-chi_.cdf(chi_squared_statistic)
print(p_val) ## 0.00012765579937978888
## 두 집단 이상에서 비교를 할 때 활용 package
from scipy.stats import chi2_contingency
chi2, p, dof, ex = chi2_contingency(ct_2)
print(f"Chi2 result of the contingency table: {chi2}, p-value: {p}")
## 결과 Chi2 result of the contingency table: 20.596749762391923, p-value: 0.00012765579937983355
'데이터 분석 기본' 카테고리의 다른 글
| 분산분석(ANOVA) 2 (0) | 2020.09.03 |
|---|---|
| 분산분석(ANOVA) 1 (0) | 2020.08.31 |
| 단순회귀분석> 잔차의 검토 (0) | 2020.08.30 |
| 단순회귀분석 > 선형관계의 강도 (0) | 2020.08.30 |
| 단순회귀분석에서의 추론 (0) | 2020.08.25 |